Michael Averbuch - Isabel F. Cruz![]() - Wendy T. Lucas - Melissa Radzyminski
- Wendy T. Lucas - Melissa Radzyminski
{averbukh,isabel,wlucas,mradzymi}@cs.tufts.edu
Information visualization tools have traditionally implemented a set
of pre-defined visual displays. We describe the DOODLE Visualization
Tool, which is interactive and supports visualizations specified by
the user with a visual constraint-based language. The main modules of
the tool comprise the syntax-directed user interface, the parser for
the user's specification, and the constraint solver. The strengths of
our approach include the expressiveness of the visual language, the
efficiency of the constraint solver, and the overall flexibility and
extensibility of the framework. The user interface is implemented
using Java and is available on the WWW.
Information visualization, an increasingly important subdiscipline within HCI [24], focuses on graphical mechanisms designed to show the structure of information and improve the cost of access to large data repositories. In printed form, information visualization has included the display of numerical data (e.g., bar charts, plot charts, pie charts), combinatorial relations (e.g., drawings of graphs), and geographic data (e.g., encoded maps) [5, 28, 29]. Computer-based systems, such as the information visualizer [6] and dynamic queries [27] have added interactivity and new visualization techniques (e.g., 3D, animation).
Other tools, such as APT [23] and SAGE [25] have focused on the automatic generation of visualizations: the appropriate display is generated based on the semantics of the underlying data (e.g., functional dependencies in a relational database in APT). Other systems that generate drawings of graphs automatically, use algorithms that take into account the graph characteristics (e.g., planarity), the preferred drawing style, and aesthetic criteria (e.g, minimization of area, maximization of the display of symmetries) [16, 18].
Declarative approaches to information visualization allow the user to specify what the displays look like but not how they are to be produced from the specification. They often combine constraints with other formalisms, such as grammars [16, 20, 30].
In databases, visualization was first used for displaying the schema and/or the database instances and to express visual queries [4]. Pioneering systems include QBE [31] and ISIS [19], while more recent systems include G+/Hy+ [15, 8] and QBD* [1]. Most systems operate on a two-step query-specification/result-visualization loop and allow only for pre-specified displays or sets of displays. Similarly to most information visualization systems, database systems lack the capability to specify visualizations tailored to the applications and to the user's preferences.
The DOODLE Visualization Tool presented in this paper
displays information in an
object-oriented database (OODB), such as O ![]() [3]. For
example, the objects in
Figure 1
belong to a database containing information
about modular programs
[3]. For
example, the objects in
Figure 1
belong to a database containing information
about modular programs
where the notation <object identity>:<class name> associates an object to the class to which it belongs. For example, oid1 and oid4 are respectively instances of the classes contains and set, and oid7 and oid8 are instances of the class procedure. Class attributes represent mappings; e.g., outer maps to the object of class module. Informally, objects of class contains represent binary relationships between modules and the procedures (or functions) they contain. The attribute members is set-valued.
DOODLE (Draw an Object-Oriented Database LanguagE) [9] is a visual database language for the declarative querying and display of object-oriented databases. By relating graphical objects to the textual objects in the database, users can specify both the selection criteria and the presentation of the queried data. Users of DOODLE arrange graphical objects and graphical constraints to form a ``picture". This picture specifies how to visualize data objects belonging to an OODB class. Taken together, the picture and class form a user-defined term, also called a U-term. The user interface is syntax-directed, therefore the user-defined specifications are syntactically correct.
The example of Figure 2 illustrates a DOODLE program,
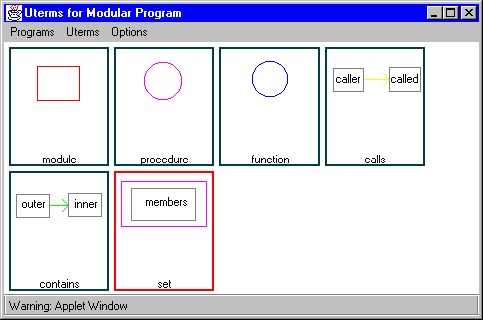
Figure 2: DOODLE program (summary).
which specifies that objects of class module are to be displayed as red boxes, objects of class procedure as purple circles, and objects of class function as blue circles. In addition, objects of class calls are to be displayed as yellow arrows that go from the ``caller'' object to the ``called'' object (similarly, objects of class contains will be displayed as green arrows). The user does not have to draw the exact shape of the objects between which the arrows will be drawn, but uses instead the key symbol refbox (for reference box), which shows the respective attribute name. Each refbox refers to the visual display(s) defined elsewhere within the same program, depending on the actual classes being represented. For example, the visualization of the objects and may be specified by the same rule (the one associated with calls). Therefore, the refbox called refers either to the display defined for the objects of class procedure or of class function; this capability is just one of the forms of genericity that DOODLE supports [10]. Finally, the display of set is specified to be the aggregate of the displays all its members. Visual aggregation is specified using a special key symbol, which in the example encloses a refbox.
The pictures that are assembled by the user are translated into text, which is then parsed. This specification is combined with the actual database to produce an incomplete description of the output graphical objects. The constraint solver will supply the missing information (i.e., the coordinates of the graphical objects).
In this paper we describe the DOODLE prototype implementation and the techniques that are used in this new approach to tailorable visualization. Some of the main characteristics of our prototype are summarized here:
User-defined visualizations of databases are also addressed by the OPOSSUM project at Wisconsin [21] and the Multiparadigmatic Visual Query project at the Universities of Rome and Pittsburg [7].
OPOSSUM is a tool for schema visualization to support database querying and browsing, which allows for user-defined variations of presentation styles (e.g., graph-based styles), with the capability of grouping as a means for visual abstraction. The styles are specified using simple declarative format where the style designer specifies textually the characteristics of the visual style. The Multiparadigmatic Visual Query project has a strong human-computer interaction component: the system helps the user to choose the preferred representation (among a set of predefined representations) according to the user's profile. Queries can be specified using different visual models (e.g., graph and/or diagram), and the transformations between these models are defined formally. The DOODLE Visualization Tool also has a formal semantics (based on the deductive database language F-logic [22]), but there are no predefined presentation styles. Unlike OPOSSUM, its focus is on visualizing the data and not the schema, and visual abstractions can be defined by the user. When compared to the other approaches, DOODLE is completely visual, and provides more control over the obtained displays, to the extent that it can specify in a precise way the drawings of important classes of graphs [12, 13].
The rest of the paper is organized as follows. In Section 2 we describe the U-terms, the DOODLE programs, and the user interaction with the interface. Section 3 presents the architecture of the prototype and a description of its modules. We conclude with an example in Section 4, and with directions for future research in Section 5.
The main graphical objects from which U-terms are composed fall into one of three categories: prototypical symbols, constraint symbols, and key symbols. Prototypical symbols include box, text, circle, straight line, arrow, and double arrow. Each of these symbols represents a visual class and is a member of the superclass visualObject. Attributes inherited from this superclass describe how prototypical symbols will appear when output by a DOODLE program.
With the exception of the class text, the visual attributes inherited from visualObject are boundary, thickness, color, and texture; text inherits only color, but has the additional attributes of value, font, and size.
All visual objects have pre-defined landmarks that serve as reference points on the boundaries of those objects. They include center (for all objects), midnorth, mideast, midsouth, and midwest (for polygons and circles), head and tail for (lines and arrows), and arrowhead and arrowtail for arrows. Figure 3 illustrates the positioning of landmarks.
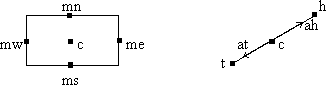
Figure 3: Cartesian and line landmarks.
User-defined reference points called anchorpoints can also be defined anywhere on the border of a visual object.
The visual class box has one additional attribute, visible, which is not inherited from visualObject. This attribute is given a value of ``true" if the box is visible. An invisible box, with a visible attribute value of ``false", may be used to represent a bounding box, which is the minimum sized boundary that can wholly contain a given set of symbols.
Spatial relationships between graphical objects are represented by constraints. When the tool generates a graphical representation of a database in response to a DOODLE program, constraints determine the layout of that representation. Two types of constraints are supported: length and overlap.
A length constraint denotes the distance between graphical objects. Its direction can be horizontal, vertical, or Euclidean, and it is drawn from a landmark or anchorpoint on one object to a landmark or anchorpoint on another object. We use a class of basic constraints over a set of variables, where linear arithmetic expressions are combined with min/max operators (e.g., to set the height of a bounding box to the maximum height of the objects it contains). The variables represent the values of other constraints in the same U-term or the value of a database attribute (so that we can set a length to be proportional to that attribute value). An overlap constraint is used to specify when one graphical object is to be placed on top of another. The second object designated by the user defaults to being on top of the first object.
Finally, key symbols specify the interpretation of prototypical symbols and constraints. These symbols include: defbox, refbox, labeled refbox, grouping box, origin, and Cartesian position.
A defbox relates a database class to all or part of the picture drawn by the user. It can contain any graphical symbol except for another defbox. Anchorpoints on its border can be associated, through the use of length constraints, with anchorpoints or landmarks on the objects within the defbox. The depiction of a database class, as defined by a defbox, can be referenced within another U-term by a refbox, or reference box. A refbox can also have anchorpoints that coincide with those on the corresponding defbox. Labeled refboxes are a specialized class of refboxes. While refboxes refer to defboxes defined in the current program, a labeled refbox permits the referencing of defboxes defined in another DOODLE program.
A grouping box is used to specify a set of visual representations. It can contain any type of symbol except for a defbox. An origin symbol is represented by the coordinates (0,0) and by a visual symbol (a small blue box), which visually specifies its location. The origin can be referenced by a length constraint to indicate the position of another object relative to it. Lastly, Cartesian position is used to define the absolute coordinates of a graphical object.
Each U-term in the DOODLE program of Figure 2
corresponds to a DOODLE rule of
the form
<U-term> <database
class>, which is to be read right to left as ``map objects of the
database class to a set of visual objects as specified by the
U-term''. In general, DOODLE rules
are of the form <set-of-terms> <set-of-terms>,
where each term can be a U-term, a database (textual) term, or a selection
term. For example, a rule of the form
<database class> <U-term> maps from pictures
to database objects, while a rule that has U-terms on both
sides expresses a mapping from pictures to pictures. Selection terms
are used to specify visualization of some objects
in a class.
DOODLE programs are declarative and therefore the order of the rules (and of the terms) is irrelevant. The meaning is formally defined using a minimal-model semantics [9, 10]. Informally, the output of DOODLE is a visualization of all the data in the database that match the search criteria (in Figure 2, the objects of <database class>).
The DOODLE Visualization Tool provides its users with a graphical interface that uses a point and click approach. The user is first prompted to select a working database from a list of all available databases. A class from that database to be visually represented by the user is then chosen.
Next, the four main components of the DOODLE interface appear on the screen. These components are the tool window (Figure 4), the input pad (Figure 5), the U-term window (Figure 6), and the output user interface window (Figure 7).
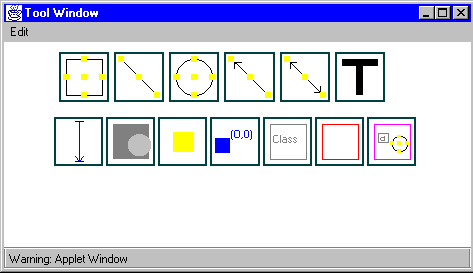
Figure 4: The tool window.
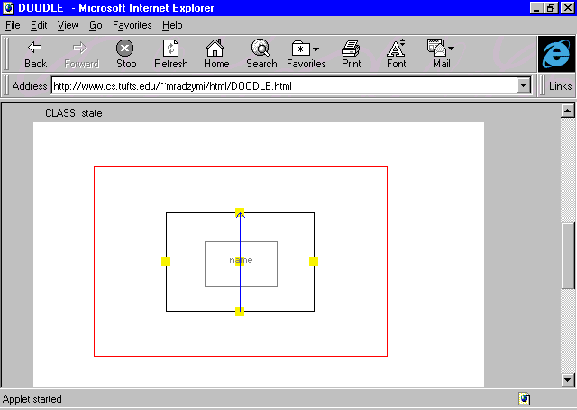
Figure 5: The input pad.
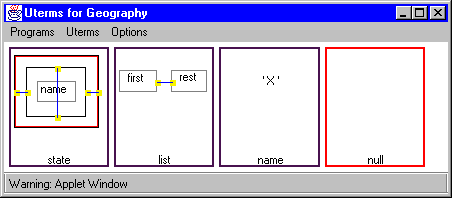
Figure 6: The U-term window.

Figure 7: The output user interface window.
The tool window contains all of the graphical objects at the user's disposal. After clicking on an object in this window, that object appears on the input pad. This pad is the drawing area where the user specifies the visual representation of the selected database class. That representation in conjunction with the class form one U-term.
The prototypical symbols available within the tool window are box, circle, straight line, arrow, double arrow, and text. After clicking on the button for one of these objects, its representation appears on the input pad, where it can be moved and re-sized. By double-clicking on any object, the attributes that denote how the selected graphical object will appear on the output pad can be specified. For all objects except text, the user can stipulate color, texture, thickness, and boundary attributes as shown in Figure 8. For text, the value, font, color, and size attributes can be specified.
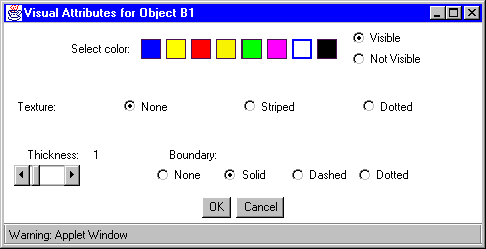
Figure 8: Window for visual attribute specification.
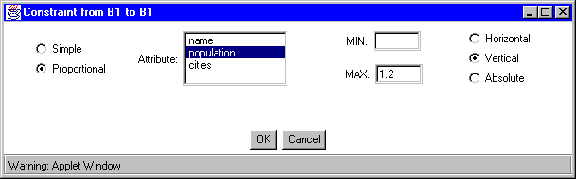
Figure 9: Specification of a proportional constraint.
In the case of the color attribute, the user can select either a particular color or ``all" colors. In the latter case, the user is then prompted for the attribute on whose value the color depends. This permits the coding of all objects with the same attribute value to have the same color.
Landmarks appear automatically on all visual objects as unlabeled yellow boxes. A user can also specify anchorpoints by clicking on their icon in the tool window and then positioning the resulting yellow box on the border of an object. The user is then prompted for an anchorpoint label.
The tool window also contains buttons for specifying graphical constraints. After clicking on the length constraint button, the user selects a landmark or anchorpoint for the start of the constraint and another such point for the end of the constraint. A window then pops up in which to define either the constraint's distance value, such as ;SPMgt; 3, or, in the case of a proportional constraint, the attribute on whose value its length depends (as shown in Figure 9). The type of constraint, i.e. absolute, horizontal, or vertical, is also selected here.
In the case of lines and arrows, an absolute constraint of length zero is assumed whenever one of the endpoints of the line or arrow is in direct contact with a landmark or anchorpoint on any other object. Attributes for this and all other constraints can be modified by double-clicking on the constraint itself (which appears as a blue arrow) or, in the case of direct contact between reference points, a blue square on the screen.
After selecting the overlap constraint button from the tool window, the user first clicks on the object to appear on the bottom, which immediately becomes shaded dark gray. The user then clicks on the object to appear on the top, which becomes shaded light gray.
The remaining three buttons in the tool window are for adding key symbols to the visual representation. A grouping box appears as a magenta-colored box that can be re-sized and re-positioned to contain only those graphical objects that represent a set. All of the objects drawn by the user on the input pad are assumed to be within a defbox. A user can explicitly select a portion of the drawing to be in a defbox by clicking on the defbox button and then re-sizing and re-positioning the box from its default value of the entire drawing area.
After clicking on the refbox button, the user is prompted for an attribute of the class of the current U-term. The depiction of the class associated with that attribute will replace the refbox on the output pad. Both defboxes and refboxes can have anchorpoints positioned on their boundaries.
A miniature rendition of the current U-term appears in the U-term window. Each time the user adds a prototypical or key symbol to the input pad, the current U-term display is updated. In the case of constraints, the user can select an operation mode in which they are displayed or one in which they are not. This window also has a pull-down menu with an option for creating a new U-term.
A file describing the current U-term is also maintained by the interface and appears in the DOODLE code window. The format, which has been defined in [14] and is shown in Figure 7, is a list stipulating the program in which the U-term appears, the class being depicted, and all the graphical objects that appear in the visualization.
The current implementation of the DOODLE Visualization Tool consists of five distinct blocks, or modules, as shown in Figure 10. The arrows in this figure represent the flow of data between modules. Following are detailed descriptions of the Parser, the Object-Oriented Database, the Constraint Solver, the Output Pad, and the data streams that connect them.
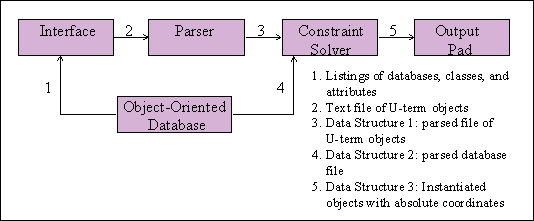
Figure 10: Block diagram of the tool implementation.
The output stream from the User Interface is parsed by this module into a data structure (Data Structure 1 in Figure 10), and stores all prototypical, constraint, and key symbols, and associates them with the program and U-terms from which they originate. The data structure is then output to the Constraint Solver module.
We use the O ![]() object-oriented database management system [3].
An object-oriented model was chosen because it
offers several advantages over its relational counterparts, including
flexibility of use and an interpreted approach [17]. The O
object-oriented database management system [3].
An object-oriented model was chosen because it
offers several advantages over its relational counterparts, including
flexibility of use and an interpreted approach [17]. The O ![]() system has the further advantage of permitting the definition of not
just objects but complex objects as well, including lists and sets.
system has the further advantage of permitting the definition of not
just objects but complex objects as well, including lists and sets.
Currently the information about the databases is kept in a parsed data
file, which contains for each database the instances of the database
schema, bindings between variable names and classes
The DOODLE Constraint Solver performs two functions: (1) it
instantiates objects from the database with the prototypical symbols
specified in the visual program, and (2) it computes the absolute
coordinates of the instantiated, by evaluating the constraints.
To instantiate the database, the Constraint Solver needs two inputs: Data
Structure 1 from the Parser, and Data Structure 2 from the database. The
database objects contained in the latter structure are stepped through one
at a time. If the class to which an object is bound has a corresponding
U-term, then that object is instantiated with the prototypical symbols that
lie within that U-term's defbox. This instantiation is then output to
Data Structure 3. Each refbox is represented in the data structure
by the symbols visualizing the class of the attribute to which it
corresponds.
If the current class has no visualization associated with it, then the
class hierarchy list contained within Data Structure 2 is checked to
find if their are any superclasses that have U-terms defined for them.
If there are, then the visualization of the most specialized
superclass is used. If not, the object is not instantiated. This
instantiation process continues until the last object in the database
has been processed.
For the length constraints,
we build a graph
where the vertices correspond to the coordinates of the reference
points whose positions are defined by length constraints,
and the edges correspond to relationships
between coordinates (which are expressed as functions that use max, min,
or the arithmetic operators).
Then we convert this graph into a directed acyclic graph. Using a
process similar to topological numbering, we compute the values of the
coordinates [12, 13].
The partial order defined by the overlap contraints
dictates the sequence in which the prototypical symbols
will be displayed.
Data Structure 3, the input to the Output Pad, contains all of the
information required to generate the user-specified visualization.
Specifically, it contains the prototypical symbols (along with their visual
attributes and their absolute coordinates) that correspond to the objects in
the database and their drawing sequence.
The Output Pad translates this data into the graphical
representation of the database, which is presented to the user
in a Java applet.
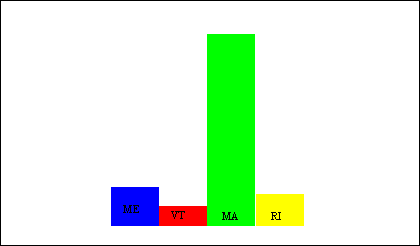
The example in Figure 6 shows how a user of DOODLE
might choose to represent the objects in a geographical database
(Figure 11). In
this example, the user wishes to create a bar chart showing population
data by state. The database has objects of class state, with
attributes name and population, and of class
list, with attributes first and rest. Although not
explicitly written, the class of the attribute values of name
is stateName, of population is integer, and of
first and rest is list.
oid1: state [name -> ME; population -> 1.2]
Figure 12: Sample database.
The visual representation of state says to represent each state by a
rectangle bearing its name, as indicated by the green refbox within
it. There are three constraints in this visualization, none of whose
values appear in the diagram. The vertical constraint has been set by
the user to be proportional to the value of the state's population.
The two horizontal constraints are of length zero and anchor the sides
of the rectangle to the red defbox surrounding it. Unseen in this
representation is the color attribute corresponding to the rectangle,
which has been set to ``all" and related to the name attribute.
This means that states with the same name will have the same color
representation, while those with differing names will be of different
colors (if running out of colors, a combination of color and texture could
be supplied).
The list U-term specifies that the representation of any class associated
with the first attribute should be placed immediately next to the
representation of any class associated with the rest attribute. The
representation for the name class is a string, as specified by the symbol
`X'. Finally, the representation for the class null is blank.
Upon completion of the above program, a text file containing all of the
prototypical symbols associated with each U-term is sent to the Parser. The
parsed file that is output by this module (Data Structure 1) is then sent to
the Constraint Solver. The solver also receives the parsed database (Data
Structure 2), which is to be instantiated with the prototypical symbols
contained in the Data Structure 1.
In instantiating the database shown in Figure 11, the first
object is of class state and the value of its name attribute is
``ME". The data structure passed from the Parser contains the
specification that the representation of a state is a rectangle
bearing the name of that state. The visual objects rectangle and text
and their associated attributes are therefore added to the text file
that will ultimately contain all the prototypical symbols representing
the instantiated database.
Next, the Constraint Solver solves all of the user-specified constraints to
determine the absolute coordinates of each prototypical symbol. The
completed data structure containing all of the symbols and their coordinates
(Data Structure 3) is then sent to the Output Pad, which generates a
visualization like the one shown in Figure 12.
Future work will focus on extending the tool to support more complex
program specifications that require the use of U-terms on the
right-hand side of the DOODLE rules (for example, the transformation
of a bar chart to a summarized bar chart or from a graph to a
containment graph [10]), implementation of polar coordinates
(e.g., to draw pie charts), and other DOODLE symbols (e.g., macro
constraints such as inclusion [11]). Other
extensions to the current interface include the implementation
and user interface aspects of inheritance and composition of DOODLE
programs [9, 10] and of underconstrained and overconstrained
specifications.
In the current implementation, only databases stored in the DOODLE
server can be visualized.
In the future, we will support access to the user's databases, or
to databases available on the WWW.
Furthermore,
we are developing an interactive tool to migrate relational databases
into object-oriented databases [2], which
will be integrated with the DOODLE Visualization Tool, to allow for the
visualization of relational databases.
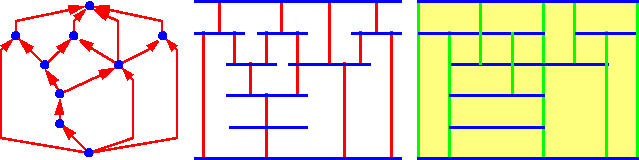
Graph drawing is an important area of application for the
DOODLE project. For example,
the pictures depicted in Figure 13 represent different
visualizations of the same planar directed acyclic graph,
Figure 13: Graph drawings.
which can be specified by DOODLE programs and drawn
in optimal time using the current constraint solver [13].
Such programs were not included here for lack of space,
and require a sophisticated user. Future topics of research
include the design of the user interface to support
a ``hierarchy'' of users: from those that
can define a complex DOODLE program to those that
want to just fine tune an existing program, but would not like
to change the main properties of
the visualization already defined (e.g., of a Pert network).
Usability studies can provide important feedback to the
current implementation and to the addition of other features
to the DOODLE Visualization Tool.
We are indebted to Andrew Forsberg and Ed Tekeian for their
preliminary prototypes of the user interface, to Ashim Garg and
Roberto Tamassia for their contributions to the constraint solver, and
to Slava Borisov and Dave Walend for helpful suggestions.
The command line arguments were: The translation was initiated by Isabel Cruz on Sun Oct 6 21:50:55 EDT 1996
A significant amount of preprocessing (on the LaTeX file) and postprocessing (on the HTML file) was performed by
Isabel Cruz.
The Constraint Solver Module
Instantiation
Evaluation
The Output Pad
An Example
oid2: state [name -> VT; population -> 0.6]
oid3: state [name -> RI; population -> 1.0]
oid4: list [first -> oid0; rest -> oid5]
oid5: list [first -> oid1; rest -> oid6]
oid6: list [first -> oid2; rest -> oid7]
oid7: list [first -> oid3; rest -> null]
Future Work
Acknowledgements
Footnotes
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Isabel Cruz
Sun Oct 6 21:50:55 EDT 1996
As You Like It: Tailorable Information Visualization
This document was generated with the help of LaTeX2HTML translator Version 96.1 (Feb 5, 1996) Copyright © 1993, 1994, 1995, 1996, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
latex2html -split 0 test.tex.